【世界初】望む結果までの手順を「説明可能な」AI、富士通研と北大が開発
会員限定記事
2021/2/5(金)
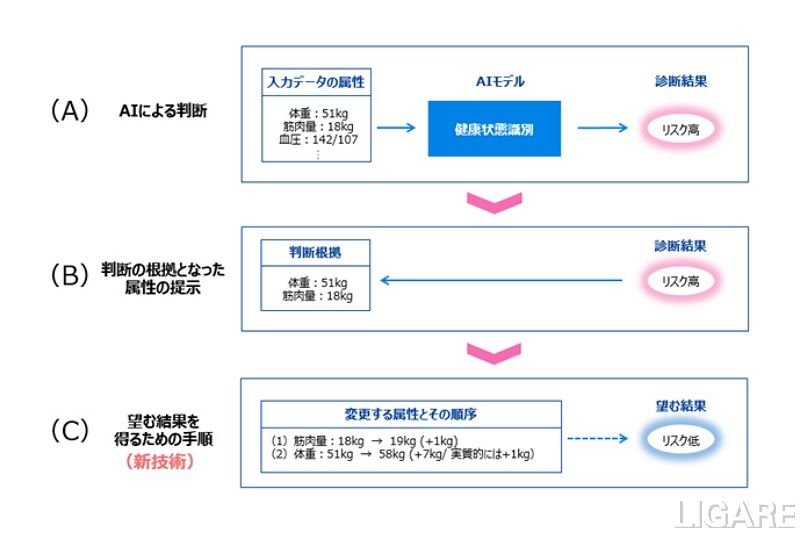
健康診断を例にした
AIによる自動判断の流れ
富士通研究所と北海道大学は共同で、AIが自動判断した結果を基に、望む結果を得るために必要な手順を自動で提示できる技術を世界で初めて開発した。
判断の根拠を提示
現在、顔認証や自動運転など高度なタスクが求められるAIシステムに広く用いられている深層学習技術は、大量のデータに基づいたさまざまな判断を予測モデルと呼ばれる一種のブラックボックス的な規則を用いて自動的に行う。しかし、社会の重要な判断や提案をAIが担うためには、AIシステムの透明性と信頼性の担保が課題となる。このような社会と技術の動向から、データに基づいて自動的に判断するだけでなく、個々の判断理由を提示する「説明可能なAI」と...