
チューリング自動運転VLAデータセットとモデル開発、一部を公開
会員限定記事
2024/9/11(水)
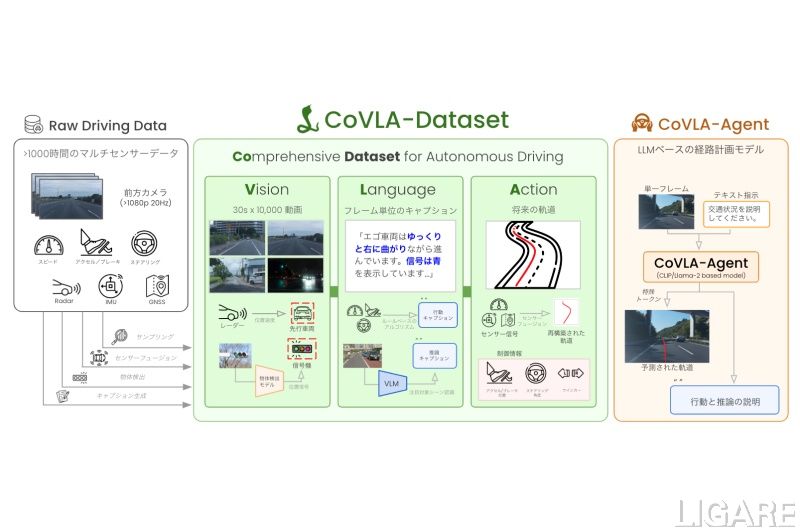
チューリング開発のデータセット、経路計画のイメージ
自動運転開発のTuringは、日本初とする自動運転向けVLA(Vision-Language-Action、視覚-言語-行動)モデルデータセット「CoVLA(読み、コブラ)Dataset」とVLAモデル「CoVLA-Agent」を開発し、一部を公開したと9月10日、発表した。また、同データセットに関する研究論文が国際会議WACV 2025に採択された。
VLAモデルは視覚(画像)、言語(テキスト)、行動のデータを統合してロボットなどが複雑な作業を実行するためのモデル。チューリングは、VLAモデルに必要なCoVLA Datasetの構築で、運転データの処理からキャプション生成を自動化し...










